
As AI-powered search systems replace traditional keyword-indexed engines, content visibility increasingly depends on a new set of structural, semantic, and credibility factors. This article examines the core determinants of how content is retrieved, cited, and ranked by large language models and generative search platforms.
Approx. 3,600 words
Peer-reviewed sources
Educational reference
Table of Contents
- Introduction to Generative Engine Optimization (GEO)
- What is Generative Engine Optimization (GEO)
- Definition of GEO
- Historical Context and the Shift to Generative Search
- How AI Search Engines Retrieve and Rank Information
- Traditional SEO vs. Generative Engine Optimization
- Core Factors Influencing Generative Engine Optimization
- Semantic SEO and Contextual Relevance
- Topical Authority and Subject Depth
- E-E-A-T in AI Search Optimization
- Content Chunking and Retrieval-Optimized Structure
- Entity-Based SEO and Knowledge Graph Alignment
- Structured Data and Schema Markup for GEO
- Conversational Search Optimization
- Citation-Worthy Content and Quotability
- Trust Signals and Credibility Architecture
- The Role of NLP and Language Model Architectures
- Challenges and Limitations of Generative Engine Optimization
- The Future of AI-Driven Search and GEO
- Frequently Asked Questions (FAQs)
20.1 What is Generative Engine Optimization (GEO)?
20.2 How does GEO differ from traditional SEO?
20.3 What content factors most influence AI search citations?
20.4 Does traditional link building matter for GEO?
20.5 What is Retrieval-Augmented Generation (RAG)?
20.6 How do I optimize content for conversational AI queries?
20.7 Is there empirical research supporting GEO practices? - Conclusion
- References
Overview
Generative Engine Optimization (GEO) is emerging as one of the most important disciplines in the modern AI-driven search landscape. As platforms such as ChatGPT, Google AI Overviews, Perplexity AI, and Microsoft Copilot increasingly replace traditional keyword-based search experiences, the way content is discovered, retrieved, ranked, and cited has fundamentally changed. Unlike traditional SEO, which primarily focuses on backlinks, keyword density, and SERP rankings, GEO focuses on optimizing content for semantic retrieval systems, Retrieval-Augmented Generation (RAG) pipelines, large language models (LLMs), and AI-powered answer engines.
This article explores the foundational principles, technical mechanisms, and core ranking factors that influence Generative Engine Optimization. It explains how modern AI search systems retrieve and evaluate information through semantic similarity, vector embeddings, entity relationships, structured data, and credibility signals such as E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness). The article also examines the role of content chunking, conversational search optimization, entity-based SEO, schema markup, NLP architectures, and citation-worthy content structures in improving AI search visibility.
In addition, the article analyzes the differences between traditional SEO and GEO, discusses the growing importance of trust and topical authority in AI retrieval systems, and highlights the challenges associated with AI search, including hallucinations, platform variability, and competitive content saturation. Supported by peer-reviewed research, technical documentation, and industry case studies, this article provides a comprehensive educational reference for understanding how AI-powered search ecosystems operate and how content creators can adapt to the future of generative search.
What is Generative Engine Optimization (GEO)
Generative Engine Optimization (GEO) refers to the practice of structuring, writing, and publishing digital content in ways that increase its probability of being retrieved, cited, and surfaced by AI-powered search and answer systems — including large language model (LLM)-based platforms such as ChatGPT, Google AI Overviews, Perplexity AI, Microsoft Copilot, and Anthropic’s Claude.
Unlike traditional search engine optimization (SEO), which was developed around keyword indexing, backlink authority, and PageRank-style algorithms, GEO addresses a fundamentally different retrieval paradigm. Generative AI engines do not merely match queries to indexed documents. Instead, they synthesize responses from vast training corpora and real-time retrieval pipelines, selecting content based on its semantic precision, structural clarity, factual authority, and alignment with the intent of user queries.
The emergence of GEO as a formal discipline accelerated between 2023 and 2025, following the widespread deployment of Search Generative Experience (SGE) by Google, the integration of web retrieval in OpenAI’s , ChatGPT, and the rise of Perplexity AI as a dedicated AI answer engine. Researchers at Princeton University, Georgia Tech, and the Allen Institute for AI began studying the characteristics of content that AI systems preferentially cited, publishing foundational work that gave rise to what is now termed the “GEO” field. Understanding the factors that influence GEO is essential for content strategists, publishers, researchers, and digital communicators operating in an increasingly AI-mediated information environment.
Definition
Generative Engine Optimization (GEO) is the set of content, structural, and credibility practices designed to improve a document’s likelihood of being retrieved, quoted, or cited by AI-driven answer engines and large language model-based search systems. It is distinct from traditional SEO in both its technical underpinnings and its evaluative criteria.

1. Historical Context and the Shift to Generative Search
The evolution from keyword-based search to generative AI retrieval represents one of the most significant transitions in information retrieval since the introduction of the hyperlink-indexed web in the 1990s. Traditional search engines — built on inverted indexing, term frequency–inverse document frequency (TF-IDF) scoring, and later PageRank — evaluated content primarily through lexical matching and inbound link authority.
Google’s BERT update (2019) and subsequent MUM (Multitask Unified Model) integration marked an early shift toward semantic understanding of search queries. However, these were evolutionary refinements within the same keyword-index paradigm. The release of ChatGPT in November 2022, and subsequent integration of web retrieval tools into LLM-based platforms, introduced a qualitatively different model: one where natural language generation, not document ranking, becomes the primary interface between users and information.
By 2024, Google’s AI Overviews feature (successor to SGE) was presenting AI-synthesized summaries at the top of search results for a substantial portion of informational queries. Perplexity AI, founded in 2022 by former members of OpenAI and Meta AI, demonstrated that a purely generative answer engine could attract tens of millions of users by citing sources rather than simply linking to them. This citation-based model placed new demands on content creators: to be cited, content must be trusted; to be trusted, it must be authoritative, well-structured, and unambiguous.
2. How AI Search Engines Retrieve and Rank Information
Understanding GEO requires understanding the underlying mechanisms by which generative AI systems select and surface information. While architectures vary across platforms, most AI search systems operate through one or more of the following pipelines:
2.1 Training Data Memorization
Large language models learn statistical patterns from massive corpora during pre-training. Content that was extensively represented in training data — including high-quality encyclopedic sources such as Wikipedia, academic publications, news from established outlets, and government documentation — is embedded into model weights. This gives well-represented, authoritative content an inherent advantage in generative retrieval, even without real-time indexing.
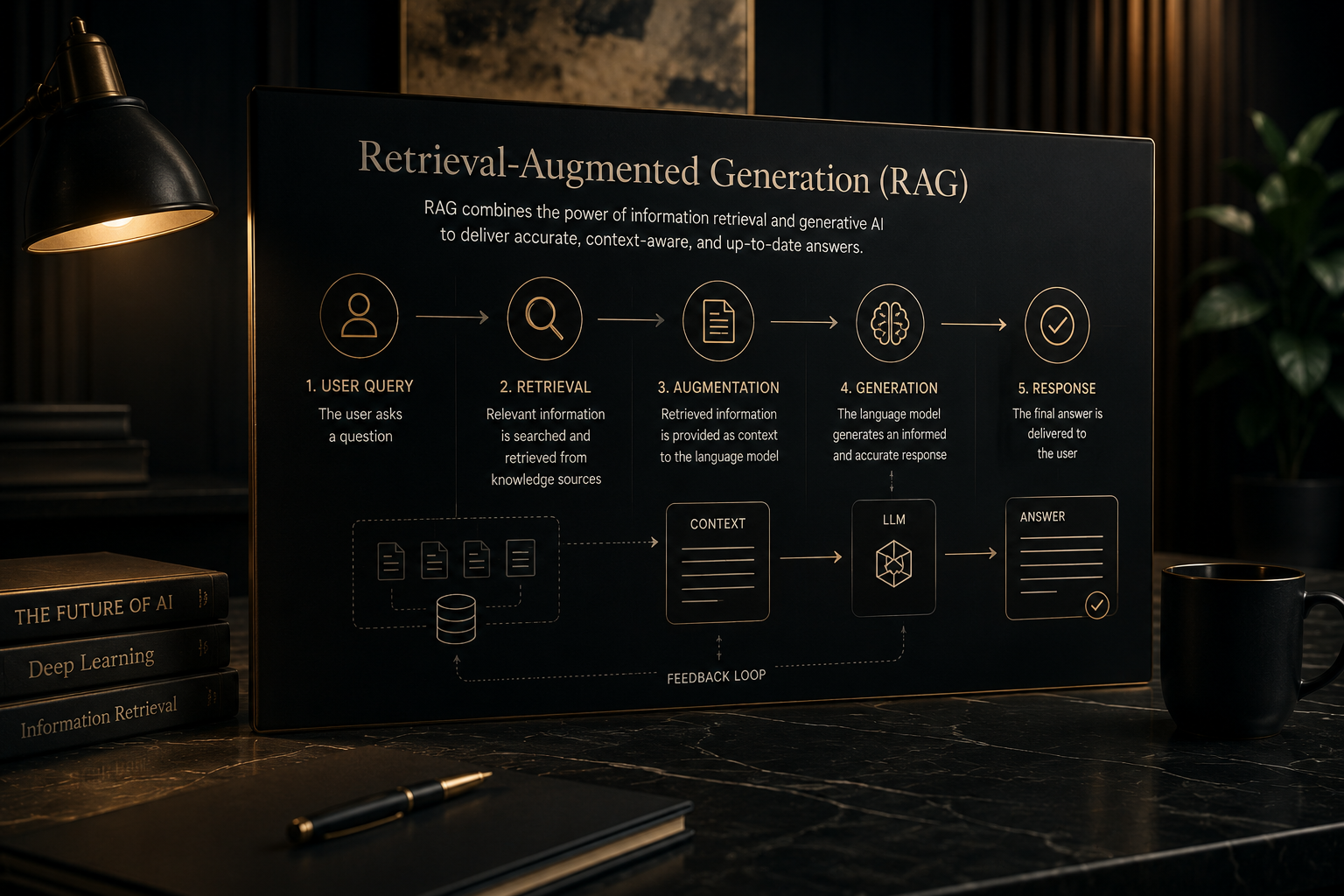
2.2 Retrieval-Augmented Generation (RAG)
Many modern AI search systems supplement LLM generation with real-time document retrieval. In a Retrieval-Augmented Generation (RAG) architecture, the system embeds the user query, retrieves semantically similar document chunks from an indexed corpus, and then conditions the language model’s generation on those retrieved passages. This means content that is well-segmented, clearly written, and topically coherent will have higher cosine similarity to relevant queries, improving retrieval probability.
2.3 Re-ranking and Citation Selection
After initial retrieval, most AI answer systems apply secondary ranking models to select which retrieved passages to cite or incorporate. These re-rankers often assess factors including source credibility signals, passage relevance, factual consistency, and recency. Platforms such as Perplexity AI display inline citations, making citation selection directly observable — a useful signal for understanding what AI systems value.
Key insight: Content optimized for AI retrieval must succeed at two distinct stages: initial semantic similarity matching (getting retrieved) and secondary credibility assessment (getting cited). GEO addresses both layers.
3. Traditional SEO vs. Generative Engine Optimization
The distinctions between classical SEO practices and GEO are substantial. The following comparison illustrates how the two disciplines diverge in their core assumptions, techniques, and success metrics.
| Factor | Traditional SEO | GEO |
| Primary retrieval mechanism | Keyword indexing, inverted index lookup | Semantic vector similarity, RAG pipelines |
| Ranking signal | Backlinks, PageRank, domain authority | Semantic clarity, entity richness, trustworthiness signals |
| Content optimization target | Keyword density, meta tags, title tags | Structured definitions, citation-worthy statements, chunk coherence |
| Authority measurement | Domain Rating (DR), inbound links | E-E-A-T signals, author credentials, institutional affiliations |
| Structural requirement | H1-H6 tags, meta descriptions, sitemaps | Self-contained sections, clear definitions, schema markup |
| Success metric | SERP position, organic click-through rate | Citation frequency, AI source inclusion, answer presence |
| Content length preference | Longer content often correlated with ranking | Precision preferred; dense, extractable passages valued |
| Link building relevance | Central ranking factor | Indirect; contributes to discoverability but not primary signal |
| Update frequency impact | Moderate; freshness signals for news content | High; recency critical for RAG-based real-time systems |
| Primary evaluation engine | Google Search Console, rank trackers | AI source monitoring tools, prompt-response testing |

4. Core Factors Influencing Generative Engine Optimization
Research and practitioner analysis have identified a set of recurring factors that determine how effectively content is retrieved and cited by generative AI systems. These factors can be grouped into five broad categories: semantic and linguistic quality, structural and technical attributes, authority and trust signals, entity and knowledge graph alignment, and content format characteristics.
Factor 01
Semantic Clarity
How precisely and unambiguously content conveys its meaning, independent of surrounding context.
Factor 02
Topical Authority
Depth and breadth of coverage on a subject domain, signaling expertise to retrieval systems.
Factor 03
Entity Density
Rich, factually accurate references to named entities that align with knowledge graph structures.
Factor 04
E-E-A-T Signals
Experience, Expertise, Authoritativeness, and Trustworthiness indicators throughout content.
Factor 05
Content Chunking
Logical segmentation of content into coherent, self-contained, extractable passages.
Factor 06
Structured Data
Schema.org markup and semantic HTML that helps AI systems parse content relationships.
4.1 Semantic SEO and Contextual Relevance
Semantic SEO, in the context of GEO, refers to the alignment of content with the conceptual meaning of user queries rather than their literal keyword representation. Large language models encode meaning in high-dimensional vector spaces, where semantically related terms cluster regardless of exact lexical overlap. Content that uses precise, contextually appropriate vocabulary — and that addresses the full semantic scope of a topic — tends to produce higher cosine similarity scores when embedded and compared against query vectors.
A document explaining a financial concept, for example, benefits not from repeating the target keyword, but from naturally incorporating related concepts, examples, mechanisms, and applications that a knowledgeable author would discuss. NLP researchers refer to this as distributional semantic richness — the property of content that, when converted to a vector representation, captures a meaningful and comprehensive region of the concept’s semantic neighborhood.
4.2 Topical Authority and Subject Depth
Topical authority refers to the degree to which a content source is perceived — by both human readers and AI systems — as a comprehensive and reliable expert on a given subject domain. AI retrieval systems, particularly those using semantic indexing, tend to favor sources that cover topics with genuine depth across multiple related subtopics, rather than sources that publish a single optimized article on a given term.
Building topical authority for GEO involves developing interconnected content clusters around a subject, ensuring that each piece contributes unique informational value rather than repeating the same core assertions. This mirrors the information architecture approach advocated by semantic web researchers, wherein a site’s content is structured as a knowledge network rather than a collection of isolated documents.
4.3 E-E-A-T: Experience, Expertise, Authoritativeness, Trustworthiness
Google’s Quality Rater Guidelines introduced the concept of E-A-T (Expertise, Authoritativeness, Trustworthiness) in 2014, later expanded to E-E-A-T with the addition of “Experience” in late 2022. While originally developed for human quality evaluation, E-E-A-T signals have become increasingly important for AI retrieval systems, which must assess source credibility without being able to read for quality in the way a human evaluator would.
- Experience signals include first-hand accounts, specific examples, case studies, and original observations that suggest a human author with practical knowledge of the subject.
- Expertise signals include technical accuracy, appropriate use of field-specific terminology, citation of primary research, and demonstration of nuanced understanding.
- Authoritativeness signals include external citations, mentions by reputable third-party sources, institutional affiliations, and author bylines with verifiable credentials.
- Trustworthiness signals include factual accuracy, transparent sourcing, absence of misleading claims, clear attribution, and the absence of promotional or sensationalist language.
AI systems that incorporate citation selection — such as Perplexity AI — have observable preferences for sources that score highly on these dimensions. Academic institutions, government agencies, established news organizations, and peer-reviewed publications consistently appear in AI citations, reflecting the model’s learned associations between source type and reliability.
4.4 Content Chunking and Retrieval-Optimized Structure
In RAG-based AI search systems, documents are segmented into chunks — typically passages of 100–500 tokens — before being embedded and stored in a vector database. During query-time retrieval, individual chunks, not entire documents, are fetched and fed to the language model. This architectural reality has significant implications for content structure.
Content optimized for chunk-based retrieval should ensure that each major paragraph or section is independently coherent — that is, capable of conveying meaningful, accurate information even when removed from the surrounding context of the full document. This is sometimes called “chunk-level informativeness.” Sections that begin with pronouns, rely heavily on earlier context, or use vague referential language (“as discussed above,” “building on this”) tend to score lower in isolation.
Practical structural recommendations include: beginning sections with clear topic sentences that define the subject of the passage; using concise, declarative statements for key claims; and ensuring that definitions, statistics, and illustrative examples appear within the same paragraph as the claim they support.
4.5 Entity-Based SEO and Knowledge Graph Alignment
Entity-based SEO centers on the recognition that modern AI search systems process information in terms of named entities — specific people, organizations, places, concepts, products, and events — and their relationships, rather than as streams of undifferentiated keywords. Google’s Knowledge Graph, Microsoft’s Bing Entity API, and the entity resolution capabilities built into modern LLMs all reflect this entity-centric view of information.
For GEO purposes, entity optimization involves accurately and consistently naming entities using their canonical forms (the names by which they are known in authoritative databases), clearly defining entity relationships within content, and aligning with structured knowledge sources. A technology article that mentions “OpenAI,” “ChatGPT,” “GPT-4,” and “Retrieval-Augmented Generation” in contextually appropriate ways provides AI systems with rich entity anchors that aid in both classification and relevance scoring.
4.6 Structured Data and Schema Markup
Structured data — most commonly implemented through Schema.org vocabulary embedded as JSON-LD in HTML documents — provides machine-readable metadata that helps AI search systems interpret the type, structure, and relationships of content. Article schema communicates authorship and publication date. FAQ schema provides directly parseable question-answer pairs. HowTo, Definition, and Event schemas offer further precision for specific content types.
While structured data does not directly affect LLM training, it significantly benefits real-time RAG systems and web crawlers that feed content into AI search pipelines. Google has explicitly acknowledged that structured data helps its AI systems better understand content, and implementations of JSON-LD FAQ schema have been shown to increase AI Overview inclusion rates for supported query types.
4.7 Conversational Search Optimization
A substantial proportion of AI search queries are phrased conversationally — as full natural language questions rather than keyword fragments. “What are the main factors that influence generative engine optimization?” reflects a fundamentally different query structure from the traditional search fragment “generative engine optimization factors.” Content that directly and precisely addresses natural language question formats tends to align better with AI query embeddings.
This has led to the incorporation of FAQ-style content sections, direct question-and-answer formatting, and what researchers call “intent-matched headers” — headings that mirror the phrasing of likely user questions. Such structural choices improve the probability that a content chunk, when retrieved, will closely match the embedded representation of a conversational query.
4.8 Citation-Worthy Content and Quotability
AI answer engines, particularly those that display source citations to users, develop implicit preferences for content that is quotable — meaning content that contains precise, discrete factual statements, clear definitions, and well-bounded claims that can be surfaced in a response without modification. Vague, hedged, or overly long sentences are less likely to be excerpted cleanly.
Citation-worthy content characteristics include: specific numerical data presented with source context; clear definitions that stand alone as informative statements; concrete comparisons and contrasts; and expert attributions to named, verifiable sources. Content that reads as though it were written to be referenced — rather than to persuade — tends to align better with AI citation criteria.
5. Trust Signals and Credibility Architecture
Beyond individual content attributes, AI retrieval systems assess credibility at the level of the publishing source. Trust signals — indicators that a source is reliable, accurate, and established — influence both the probability of initial inclusion in AI training datasets and the weight given to retrieved content during generation.
- HTTPS and technical security: Secure sites signal basic operational legitimacy to crawlers and AI indexers.
- Publication history and consistency: Sources with long track records of accurate, non-promotional content accumulate implicit trust in training data over time.
- Author attribution and credentials: Named authors with verifiable professional backgrounds and institutional affiliations increase trustworthiness perception.
- Transparent editorial standards: Clear editorial policies, correction notices, and source disclosure norms reflect practices associated with institutional journalism and academic publishing.
- Third-party mentions: External citations, press coverage by reputable outlets, and academic reference enhance a source’s perceived authority.
- Absence of misleading signals: Content free from sensationalism, exaggerated claims, undisclosed sponsorships, and factual errors is less likely to be filtered out by AI safety systems.
6. The Role of NLP and Language Model Architectures
The specific characteristics of large language model architectures — transformer-based neural networks trained on autoregressive or masked language modeling objectives — shape what kinds of content they represent effectively. Transformers, including GPT-4 (OpenAI), Gemini (Google DeepMind), Claude (Anthropic), and open-source models such as LLaMA, encode text as sequences of token embeddings processed through multi-head self-attention layers.
This architecture means that content with clear logical structure, consistent referential chains, and bounded semantic units is more faithfully represented than content with dense cross-references, heavy anaphora, or highly context-dependent meaning. Natural language processing (NLP) research has demonstrated that transformer-based models develop stronger representations for content that closely resembles the formal, structured prose found in encyclopedic and instructional writing — the same register that Wikipedia, academic textbooks, and technical documentation employ.
The implication for content creators is that adopting a register similar to high-quality reference writing — clear, objective, precise, and formally structured — produces content that is intrinsically more compatible with LLM representation and retrieval.
7. Challenges and Limitations of Generative Engine Optimization
Despite the growing interest in GEO as a discipline, it faces several significant challenges that distinguish it from the more established field of traditional SEO.
7.1 Opacity of AI Retrieval Systems
Unlike traditional search engines, which publish Webmaster Guidelines and provide rank-tracking data through tools such as Google Search Console, most AI search platforms do not disclose the specific factors used in retrieval or citation selection. This opacity makes empirical GEO optimization difficult to verify and limits the field’s ability to develop rigorous evidence-based practices.
7.2 Variability Across Platforms
Different AI search systems — including ChatGPT with browsing, Google AI Overviews, Perplexity AI, and Microsoft Copilot — use distinct retrieval architectures, indexing pipelines, and citation criteria. Content that performs well in one system may not transfer predictably to another, complicating cross-platform optimization strategies.
7.3 Hallucination and Factual Confabulation
A known limitation of generative AI systems is their tendency to produce plausible-sounding but factually incorrect statements — a phenomenon known as hallucination. This means that even well-optimized, authoritative content can be misrepresented or inaccurately cited by AI systems, undermining the reliability of AI search as an information delivery mechanism and creating reputational risks for misquoted sources.
7.4 Competitive Saturation and Content Dilution
As awareness of GEO grows, the volume of content designed to match AI retrieval criteria increases. This creates a form of competitive saturation analogous to the keyword stuffing era of early SEO, where optimized but low-quality content risks diluting AI training and retrieval corpora. Platforms have begun developing countermeasures, including AI-generated content detection and heightened source quality filters.
7.5 Ethical and Epistemological Concerns
The concentration of information flow through a small number of AI platforms raises legitimate concerns about epistemic homogenization — the possibility that diverse perspectives and minority viewpoints are systematically underrepresented in AI-generated answers. Researchers in information science and media studies have noted that GEO, if practiced primarily by well-resourced institutional actors, may further concentrate informational authority and disadvantage smaller or independent publishers.

8. The Future of AI-Driven Search and GEO
The trajectory of AI-driven search suggests that GEO will become an increasingly central discipline for anyone producing content intended for wide distribution. Several developments are likely to shape the field in the near term.
Multimodal retrieval — the ability of AI systems to retrieve and generate responses based on images, audio, and video in addition to text — will expand GEO considerations beyond written content. AI systems developed by Google (Gemini), OpenAI (GPT-4o), and Anthropic (Claude) have already demonstrated multimodal capabilities that will eventually be integrated more fully into search experiences.
Agentic AI systems — AI agents that autonomously browse the web, execute tasks, and synthesize information from multiple sources — represent a further evolution in how content will be discovered and consumed. In agentic contexts, content must not only be retrievable but must also be structured in ways that support programmatic extraction and integration into multi-step reasoning processes.
The development of better AI source attribution standards — analogous to academic citation norms — is also under active discussion among AI platform developers and policymakers. If standardized citation formats and source transparency requirements emerge, they will likely create new structured signals for GEO optimization. The evolution of the semantic web, linked data standards, and knowledge graph integration will further deepen the connection between well-structured, entity-rich content and AI system preferences.
Frequently Asked Questions
What is Generative Engine Optimization (GEO)?
Generative Engine Optimization (GEO) is the practice of structuring and writing digital content to increase its probability of being retrieved, cited, or quoted by AI-powered search and answer systems, including ChatGPT, Google AI Overviews, Perplexity AI, and similar platforms. It differs from traditional SEO in that it targets LLM retrieval mechanisms rather than keyword-indexed ranking algorithms.
How does GEO differ from traditional SEO?
Traditional SEO focuses on ranking web pages in keyword-indexed search results through link building, metadata optimization, and keyword placement. GEO focuses on making content semantically retrievable and citation-worthy within AI-driven answer engines, which use vector similarity, RAG pipelines, and credibility signals rather than link-based ranking. The success metric in GEO is citation or source inclusion, not SERP position.
What content factors most influence AI search citations?
Key factors include semantic clarity (precise, unambiguous language), topical depth (comprehensive subject coverage), strong E-E-A-T signals (experience, expertise, authoritativeness, and trustworthiness), well-structured chunk-level passages (independently coherent sections), entity accuracy (correct use of named entities and their relationships), and structured data markup using Schema.org vocabularies.
Does traditional link building matter for GEO?
Link building retains indirect relevance for GEO in that inbound links contribute to a domain’s discoverability and its representation in AI training data. However, link authority is not a direct ranking signal in most AI retrieval architectures. Semantic quality, source credibility, and structural precision have greater direct impact on AI citation likelihood than link profiles.
What is Retrieval-Augmented Generation (RAG) and why does it matter for GEO?
Retrieval-Augmented Generation (RAG) is an AI architecture in which a language model retrieves relevant document chunks from a vector-indexed corpus before generating a response. Content is segmented and embedded as vectors; at query time, chunks with high cosine similarity to the query are retrieved and fed to the model. Content that is well-chunked, semantically rich, and independently coherent performs better in RAG-based systems.
How do I optimize content for conversational AI queries?
Optimizing for conversational queries involves structuring content to directly address natural language questions, using intent-matched headings that mirror likely question phrasing, providing clear and concise direct answers within the first few sentences of each section, and incorporating FAQ-style content blocks. Precision and directness in addressing specific questions is prioritized over general narrative prose.
Is there empirical research supporting GEO practices?
Early formal research on GEO was published by researchers at Princeton University and
, studying citation patterns in AI search systems. The field is growing, though it remains methodologically constrained by the opacity of AI retrieval architectures. Practitioners supplement academic research with observational studies of citation patterns in platforms like Perplexity AI, where source inclusion is publicly visible.
Conclusion
Generative Engine Optimization represents a necessary evolution in how content creators, researchers, publishers, and digital communicators approach the problem of information visibility in an AI-mediated search environment. As platforms such as Open AI’s ChatGPT, Google AI Overviews, Perplexity AI, and Anthropic’s Claude increasingly mediate how people access and consume information, the factors that determine whether content is retrieved and cited by these systems become critically important.
The core factors influencing Generative Engine Optimization are not arbitrary platform-specific quirks, but reflect the underlying mechanics of how large language models encode meaning, retrieve relevant passages, and assess source credibility. Semantic precision, topical depth, structural clarity, entity accuracy, E-E-A-T signals, and citation-worthy content construction each address real characteristics of LLM retrieval architectures. Understanding and applying these factors allows content creators to produce material that is not only accurate and useful to human readers, but also effectively communicated to the AI systems that increasingly serve as intermediaries between information and audiences.
The field will continue to evolve as AI search architectures develop, agentic capabilities expand, and multimodal retrieval matures. Practitioners who ground their GEO strategies in the genuine mechanics of AI information retrieval — rather than in speculative optimization tactics — are best positioned to maintain content visibility in this changing landscape. Ultimately, the factors that make content excellent for human readers — clarity, accuracy, depth, and trustworthiness — remain foundational to GEO, suggesting that quality-first content strategies are structurally aligned with AI retrieval optimization.
References
-
No. Reference What It Means in Simple Words Why It Matters in Your Blog 1 GEO: Generative Engine Optimization by Aggarwal et al. Research paper explaining how AI search engines rank and cite content. This is the strongest academic proof for GEO as a real concept. 2 Google Search Central — AI-generated content guidance (2022) Google explains how AI-written content should follow quality rules. Supports your points about quality, trust, and useful content. 3 Google (E-E-A-T) Google’s official quality framework for evaluating websites. Important for explaining Experience, Expertise, Authority, and Trust. 4 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. Introduced the RAG system where AI retrieves real documents before answering. Critical for explaining how AI search engines fetch information. 5 Augmented Language Models: a Survey by Mialon et al. Survey of advanced AI language model systems and retrieval methods. Gives technical credibility to your AI retrieval explanations. 6 Open AI — GPT-4 Technical Report (2023) Official document explaining GPT-4 model capabilities and limitations. Supports sections about LLM architecture and AI-generated answers. 7 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by Devlin et al. Famous NLP paper introducing BERT language understanding. Helps explain the shift from keyword SEO to semantic search. 8 Perplexity AI documentation AI search platform showing citation-based answers. Real-world example of GEO in action. 9 Google DeepMind — Gemini Technical Report (2023) Explains Google’s multimodal AI model Gemini. Supports discussion about modern AI search systems. 10 Anthropic — Claude Documentation (2024) Documentation for Claude AI and Constitutional AI system. Adds credibility to sections discussing AI answer engines. 11 Schema.org Consortium Official structured data vocabulary used on websites. Important for schema markup and AI-readable content sections. 12 A Taxonomy of Web Search by Andrei Broder Classic research paper about different types of search intent. Useful for explaining conversational and intent-based AI search.
More blog by MARKESTRA